- 第一回 Docker編
- 第二回 Docker Compose/Dockerfile編
- 第三回 Kubernetes入門編
- 第四回 Kubernetes基礎編
- 第五回 Kubernetes応用編
- 第六回 Helm編
今回は以下のサンプルアプリケーションをminikubeにデプロイするためのマニフェストや手順について説明します。
https://github.com/kwhrtsk/rails-k8s-demoapp
前提
準備
まずサンプルアプリのコードをチェックアウトしてminikubeを起動してください。(前回と同じなのですでにやっている人は読み飛ばしてください)
# サンプルアプリのコードをチェックアウト$ git clone https://github.com/kwhrtsk/rails-k8s-demoapp.git$ cd rails-k8s-demoapp# minikubeを起動$ minikube start --cpus=3 --memory=2048 --vm-driver=hyperkit --disk-size=12g# kubernetesのダッシュボードをオープン$ minikube dashboard概要
前回は下記について説明しました。
- APIオブジェクトを定義するマニフェストファイルをYAML形式で記述する方法
- マニフェストファイルと
kubectlコマンドを使ってAPIオブジェクトを管理する方法
今回は実際にRailsアプリをMySQLやRedisなどのミドルウェアも含めて丸ごとk8sクラスタ上にデプロイするための手順を説明します。一度に多種のAPIオブジェクトを使うと全体を理解するのが難しくなるので、4つのステップに分けて進めます。
Step1では、第2回Docker Compose/Dockerfile編のdocker-compose-preview.ymlに相当する構成をできるだけ少ないAPIオブジェクトで簡潔に記述します。この時点では簡潔さと引き換えにいくつかの制約がありますが、それらをStep2からStep4で解消していきます。
今回のKubernetes基礎編ではStep1を説明し、次回のKubernetes応用編でStep2以降を説明します。
Railsアプリのイメージをminikube上で使えるようにする方法
マニフェストの説明に入る前に、ビルドしたRailsアプリのイメージをminikube上にデプロイできるようにする方法を説明します。
いくつかの方法があります。
- Docker Hubのようなパブリックレジストリに登録する。
- AWSのECRやGCPのContainer Registryのようなプライベートレジストリサービスに登録する。
- プライベートレジストリサービスを自前で用意してそこに登録する。
- minikube VM上のDockerプロセス上に接続して直接イメージをビルドする。
今回は一番簡単な4の方法を使います。
準備 の節を参照して、サンプルコードをチェックアウトしminikubeを起動したら、下記のコマンドを実行してください。
$ (eval $(minikube docker-env) && docker build . -t demoapp:0.0.1)minikube docker-envコマンドは、minikube VM上のDockerプロセスに接続できるようにするための環境変数を出力します。上記のようにすることでminikube VM上のDockerプロセス上で直接イメージをビルドします。これにより、マニフェストではイメージ名をdemoapp:0.0.1と指定すればこのイメージを使えるようになります。
この方法を使う場合、タグにはlatest以外の値を指定してください。k8sの仕様で、タグがlatestになっているイメージを指定するとコンテナの起動前に必ずレジストリからイメージをpullしようとするため、4の方法だと必ず失敗するようになってしまいます。
これは4の方法を使う場合の制約ではあるのですが、インフラの構成管理という観点ではそもそもイメージのタグにlatestを使うとデプロイされるバージョンがタイミング依存になるため、4以外の方法でもlatestタグの使用は避けたほうが良いと思います。
Step1: Deployment, Service, ConfigMap, Secret
Step1では、第2回Docker Compose/Dockerfile編のComposeファイルdocker-compose-preview.ymlに相当する構成を(いくつかの制約と引き換えに)できるだけ簡潔に記述します。
# docker-compose-preview.ymlversion: "3"services: puma: image: demoapp build: context: . env_file: - .dockerenv/rails ports: - 3000:3000 depends_on: - mysql - redis command: ./bin/setup-db-and-start-puma sidekiq: image: demoapp env_file: - .dockerenv/rails depends_on: - puma command: ./bin/start-sidekiq mysql: image: mysql:5.7.21 env_file: - .dockerenv/mysql redis: image: redis:4.0.9 command: redis-server --appendonly yesこのComposeファイルの要点は下記の通りです。
- puma, sidekiq, mysql, redisの4つのサービス(コンテナ)を起動
- puma, sidekiqコンテナに設定する環境変数は
.dockerenv/railsにまとめて記述 - mysqlコンテナに設定する環境変数は
.dockerenv/mysqlにまとめて記述 - pumaコンテナには3000番ポートで接続可能
- データベーススキーマの初期化(
rails db:setup)はpumaコンテナの起動時に実行- 詳細は前回の記事の
./bin/setup-db-and-start-pumaの解説を参照
- 詳細は前回の記事の
これと同等の構成をk8sで実現するために、Deployment、Service、ConfigMap、Secretの4種類のAPIオブジェクトを使います。
Deploymentは、Pod(≒コンテナ)の起動管理を行うオブジェクトです。Serviceは、PodへアクセスするためのI/Fを提供します。この二つは前回のKubernetes入門編で解説したので詳細はそちらを参照してください。
DeploymentとServiceの組み合わせで、Docker Composeにおけるserviceに相当する機能になります。今回の例だと、mysql, redis, pumaのサービスには外部のコンテナまたはクラスタの外部(ブラウザ)からアクセスする必要があるため、DeploymentとServiceを一組ずつ定義します。sidekiqは外から参照する必要がないため、Deploymentのみ定義します。
ConfigMapとSecretは、Deploymentに設定する環境変数の管理に使います。今回の使い方ではComposeファイルにおける.dockerenv/mysqlと.dockerenv/railsに相当します。
使用するマニフェストファイルは以下の11個で、全てk8s/manifests-step1/に置いてあります。一つのYAMLファイルに一つのAPIオブジェクトの定義を書いています。
- mysql-deploy.yaml
- mysql-env-cm.yaml
- mysql-env-secret.yaml
- mysql-svc.yaml
- redis-deploy.yaml
- redis-svc.yaml
- puma-deploy.yaml
- puma-svc.yaml
- rails-env-cm.yaml
- rails-env-secret.yaml
- sidekiq-deploy.yaml
これから順に内容を説明していきますが、まずはデプロイを実行してみましょう。
準備 の節を参照して、サンプルコードをチェックアウトしminikubeを起動したら、下記のコマンドを実行してください。デプロイが済んだ後、ブラウザでサンプルアプリを開くことができます。
# Railsアプリのイメージをビルド$ (eval $(minikube docker-env) && docker build . -t demoapp:0.0.1)$ cd k8s/manifests-step1# APIオブジェクトを作成$ cat *.yaml | kubectl apply -f -# pumaとsidekiqの起動が完了するまで待機$ kubectl rollout status deploy demoapp-puma$ kubectl rollout status deploy demoapp-sidekiq# puma serviceのエンドポイントをブラウザでオープン$ minikube service demoapp-puma上記の手順と等価なタスクをMakefileに定義してあるので、代わりにmakeコマンドで実行することもできます。
$ cd k8s/manifests-step1$ make kubectl-apply$ make kubectl-rollout-status$ make minikube-service# またはパラメータなしの make で全て順に実行APIオブジェクトを削除するには次のようにします。
$ cd k8s/manifests-step1$ cat *.yaml | kubectl delete -f -# または make cleanMakefileは下記のような内容です。GNU Makeで動作を確認しています。
# k8s/manifests-step1/MakefileSHELL = /bin/bashall: $(MAKE) minikube-docker-build $(MAKE) kubectl-apply $(MAKE) kubectl-rollout-status $(MAKE) minikube-serviceclean: kubectl-deleteminikube-docker-build: eval $$(minikube docker-env) && docker build ../../ -t demoapp:0.0.1kubectl-apply: cat *.yaml | kubectl apply -f -kubectl-rollout-status: kubectl rollout status deploy demoapp-puma kubectl rollout status deploy demoapp-sidekiqminikube-service: minikube service demoapp-pumakubectl-delete: cat *.yaml | kubectl delete -f -スクリプト化するまでもないような短いコマンドであっても、定型的な処理はこのように形として残しておくのがおすすめです。こういった小さな積み重ねがチーム内に暗黙知が生まれることを防ぎます。
次に、各マニフェストファイルの内容を説明します。
mysql-deploy.yaml: mysql の Deployment
はじめにMySQLに関連するマニフェストの内容を説明します。
まずは Deployment から。
# k8s/manifests-step1/mysql-deploy.yaml---apiVersion: apps/v1kind: Deploymentmetadata: name: demoapp-mysql labels: app: demoapp component: mysqlspec: replicas: 1 selector: matchLabels: app: demoapp component: mysql template: metadata: labels: app: demoapp component: mysql spec: restartPolicy: Always containers: - name: mysql image: mysql:5.7.21 livenessProbe: tcpSocket: port: 3306 readinessProbe: tcpSocket: port: 3306 envFrom: - configMapRef: name: demoapp-mysql-env - secretRef: name: demoapp-mysql-env最初なので全般事項についてもここで説明します。
.metadata.nameにはdemoapp-mysqlのようにdemoapp-というプレフィクスをつけます。例えば、Serviceオブジェクトの名前をredisにしてしまうと、それ以降に起動する全てのコンテナにk8sによってREDIS_PORTのような環境変数が設定されるのですが、sidekiqなど一部のgemはこういった環境変数によって動作が変わってしまう場合があります。名前のプレフィクスはこのような環境変数とgemなどで一般的に使用される環境変数が競合するのを避けるのが目的です。自動設定される環境変数の詳細についてはドキュメントを参照してください。- 各種ラベルには、共通で
appラベルにdemoappを、コンポーネントごとにcomponentラベルを設定します。コンポーネントはpuma,sidekiq,mysql,redisなどです。 - 同一のコンポーネントに属するAPIオブジェクトには、同一の名前とラベルを設定します。例えば、
mysql用のDeployment、Serviceには.metadata.nameに共通のdemoapp-mysqlという名前をつけます。また、.metadata.labelsにはapp: demoapp,component: mysqlの二つを設定します。 - マニフェストのファイル名には、コンポーネントとAPIオブジェクトの種類の略称を使います。例えば
mysqlのDeploymentであればmysql-deploy.yamlとなります。略称については 前回のkubectl getの節を参照してください。
次に、mysqlのための固有の設定について説明します。
livenessProbeとreadinessProbeは、コンテナの死活監視のための設定項目です。この例では3306番ポートにTCP接続できるかどうかで判定を行なっています。また、上記では使用していませんが、それぞれinitialDelaySeconds(最初に検査を行うまでの待機秒数)やperiodSeconds(検査の間隔: デフォルト10秒)などの項目を設定することができます(詳細)。また、コマンドを実行したりHTTPリクエストを投げることもできます。
livenessProbeで死亡判定されると、ReplicaSetはrestartPolicyに基づいてそのPodの再起動か再作成を試みます。条件が厳しすぎるとプロセスの起動処理中に強制的に再起動されていつまで経っても起動しなくなります。その場合はinitialDelaySecondsなどの値を緩めるなどして調整する必要があります。
readinessProbeはServiceオブジェクトがそのPodに接続リクエストを転送するかどうかの判定に使います。こちらは起動直後のPodにリクエストを転送するのを防ぐことなどを目的に使用します。
envFromは環境変数を設定するための項目です。この例では ConfigMap と Secret という別のAPIオブジェクトを参照して環境変数を設定しています。ConfigMapとSecretについては後述します。
envを使うと直接Deploymentの定義の内部に環境変数を定義することもできます。詳細は下記を参照してください。
Define Environment Variables for a Container | Kubernetes
mysql-svc.yaml: mysql の Service
続いてmysql-service.yamlの内容を説明します。
# k8s/manifests-step1/mysql-svc.yaml---apiVersion: v1kind: Servicemetadata: name: demoapp-mysql labels: app: demoapp component: mysqlspec: ports: - protocol: TCP port: 3306 selector: app: demoapp component: mysql.spec.selectorにappとcomponentという二つのラベルを指定しています。これはmysql-deploy.yamlの.spec.template.metadata.labelsと一致させる必要があります。
前回のKubernetes入門編ではappというラベル一つでDeploymentとServiceを接続していましたが、今回はDeploymentがmysqlの他にredisやpumaなど複数存在するため、app: demoappというラベルだけだとmysqlのServiceがredisやpumaのPodを参照して混線することになります。これを避けるためにappとcomponentという二つのラベルをセレクタに指定しています。
mysql-env-cm.yaml: mysqlの環境変数用ConfigMap
次にmysql-env-cm.yamlを説明します。
# k8s/manifests-step1/mysql-env-cm.yaml---apiVersion: v1kind: ConfigMapmetadata: name: demoapp-mysql-envdata: MYSQL_USER: demoapp MYSQL_DATABASE: demoapp_productionConfigMapは環境変数や設定ファイルなどアプリケーションのパラメータを管理するためのAPIオブジェクトです。使用形態には大まかに3つの方法があります。
envFromで丸ごと環境変数に設定する。envでキーを指定して個別に環境変数に設定する。- キーを指定して値をファイルとして
Pod上のファイルにマウントする。
mysql-deploy.yamlでは1の方法を使っています。関係ある部分だけ抜き出すと下記の通りです。
# k8s/manifests-step1/mysql-deploy.yaml---spec: template: spec: containers: - name: mysql image: mysql:5.7.21 envFrom: - configMapRef: name: demoapp-mysql-env # ConfigMapの `.metadata.name` を指定このように参照すると、ConfigMapの.dataの各エントリが全て環境変数として設定されます。
2の方法で同じことをしようとすると下記のようになります。
# k8s/manifests-step1/mysql-deploy.yaml---spec: template: spec: containers: - name: mysql image: mysql:5.7.21 env: - name: MYSQL_USER # 環境変数名を指定 valueFrom: configMapKeyRef: name: demoapp-mysql-env # ConfigMapの`.metadata.name`を指定 key: MYSQL_USER # ConfigMapの`.data`エントリのキーを指定 - name: MYSQL_DATABASE valueFrom: configMapKeyRef: name: demoapp-mysql-env key: DATABASEだいぶ冗長になりました。envFromは比較的最近追加された機能なので以前はこの方法で書いていましたが大変でした。ConfigMapはできるだけ用途に応じた単位で分割して、envFromを使えるようにした方が良いと思います。
3の方法は、例えば/etc/mysql/my.cnfのような設定ファイルをConfigMapで管理する方法です。.dataエントリに定義した値をファイルとしてPod上の任意のパスにマウントすることができます。この方法についてはこのドキュメントでは扱いませんので、詳細は下記の資料を参照してください。
Configure a Pod to Use a ConfigMap | Kubernetes
ConfigMapとSecretについては、APIオブジェクトの名前(.metadata.name)を${プレフィクス}-${コンポーネント}の形式ではなく、さらに-envを付け加えてdemoapp-mysql-envのような形にしています。これは将来的に環境変数に加えて3の方法で設定ファイルを追加する場合に名前が競合するのを防ぐ意図があります。(設定ファイル用のConfigMapを追加する場合はdemoapp-mysql-confのような名前にするのが良いと思います)
mysql-env-secret.yaml: mysqlの環境変数用Secret
最後にmysql-env-secret.yamlを説明します。
# k8s/manifests-step1/mysql-env-secret.yaml---apiVersion: v1kind: Secretmetadata: name: demoapp-mysql-envdata: MYSQL_PASSWORD: c2VjcmV0 # echo -n "secret" | base64 MYSQL_ROOT_PASSWORD: dG9wc2VjcmV0 # echo -n "topsecret" | base64SecretはConfigMap同様キー・バリュー形式で設定値を管理できるAPIオブジェクトですが、パスワードやクレデンシャルなど機密性の高い情報を管理することを前提としています。
Secretは、ConfigMapと比較すると表面的には下記の点が異なります。
.dataエントリに値を書き込むときはBASE64エンコードして書く必要がある。- Dashboard上ではデフォルトで値が表示されないようになっている。(クリックで表示させることはできる)
- GCPのConsole上だと表示できない
また、Secretの中身はPodのtmpfs上に展開されディスクには書き込まれないなど、内部的にはConfigMapよりも安全性に配慮された運用が行われます。セキュリティ上の制限については下記のドキュメントを参照してください。
Encrypting Secret Data at Rest | Kubernetes
Deploymentからの参照方法はほとんどConfigMapと同じなので説明を割愛します。configMapRefの代わりにsecretRefを使う必要がある点にだけ注意してください。
なお、SecretオブジェクトのマニフェストファイルにはBASE64エンコードしただけの値を書いているので平文で機密情報を書いているのと同じです。通常はこのままgitリポジトリにコミットすることはしません。実際の運用の際には sopsやyaml_vault とGCP/AWSのKMSで暗号化するのがおすすめですが、それについてはHelm編で紹介したいと思います。
redis-deploy.yaml: redis の Deployment
次にRedisに関連するマニフェストの内容を説明します。
まずは Deployment から。
# k8s/manifests-step1/redis-deploy.yaml---apiVersion: apps/v1kind: Deploymentmetadata: name: demoapp-redis labels: app: demoapp component: redisspec: replicas: 1 selector: matchLabels: app: demoapp component: redis template: metadata: labels: app: demoapp component: redis spec: restartPolicy: Always containers: - name: redis image: redis:4.0.9 livenessProbe: tcpSocket: port: 6379 readinessProbe: tcpSocket: port: 6379 command: - redis-server - --appendonly - "yes"構造としては mysql-deploy.yaml とほとんど同じです。
commandに関しては、docker-compose-preview.yamlでは下記のように文字列のエントリとして定義していましたが、k8sのマニフェストでは上記の通り配列として定義する必要がある点に注意してください。
services: redis: image: redis:4.0.9 command: redis-server --appendonly yesredis-svc.yaml: redis の Service
続いて Service の内容を確認します。
# k8s/manifests-step1/redis-svc.yaml---apiVersion: v1kind: Servicemetadata: name: demoapp-redis labels: app: demoapp component: redisspec: ports: - protocol: TCP port: 6379 selector: app: demoapp component: rediscomponentとポート番号が違うだけでmysqlのものとほとんど同じです。特筆すべき点はありません。
puma-deploy.yaml: puma の Deployment
いよいよRailsアプリ本体のためのマニフェストの説明に移ります。
まずはpuma用のDeploymentから説明します。
# k8s/manifests-step1/puma-deploy.yaml---apiVersion: apps/v1kind: Deploymentmetadata: name: demoapp-puma labels: app: demoapp component: pumaspec: replicas: 1 selector: matchLabels: app: demoapp component: puma template: metadata: labels: app: demoapp component: puma spec: restartPolicy: Always containers: - name: puma image: demoapp:0.0.1 imagePullPolicy: IfNotPresent command: - ./bin/setup-db-and-start-puma livenessProbe: httpGet: path: /health_check/full port: 3000 initialDelaySeconds: 30 readinessProbe: httpGet: path: /health_check/full port: 3000 initialDelaySeconds: 30 envFrom: - configMapRef: name: demoapp-rails-env - secretRef: name: demoapp-rails-envimageにはdocker buildコマンドで指定したイメージ名を指定します。imagePullPolicyはIfNotPresentを指定します。前述の通りこのイメージはレジストリに登録していないためです。commandにはdocker-compose-preview.ymlと同じく./bin/setup-db-and-start-pumaを指定します。これはpumaの起動前にrails db:setupを試みるスクリプトです。詳細は第2回の記事で説明しました。livenessProbeとreadinessProbeではそれぞれ/health_check/fullというパスを指定しています。このサンプルアプリではhealth_checkというgemで死活監視用のエンドポイントを実装しています。このパスを叩くだけでMySQLやRedisとの接続検証を行うことができるようになります。envFromでは、demoapp-rails-envという名前のConfigMapとSecretを参照しています。これらのオブジェクトはdocker-compose-preview.ymlにおけるenv_fileに相当する環境変数の設定を保持しています。
puma-svc.yaml: puma の Service
次にpuma用のServiceの定義を確認します。
# k8s/manifests-step1/puma-svc.yaml---apiVersion: v1kind: Servicemetadata: name: demoapp-puma labels: app: demoapp component: pumaspec: type: NodePort ports: - protocol: TCP port: 3000 selector: app: demoapp component: puma.spec.typeにNodePortを指定しています。mysqlやredisと異なり、pumaの接続相手は他のコンテナではなくクラスタの外にあるブラウザです。そのため、クラスタ内での通信のためのエンドポイントを生成するClusterIPの代わりにNodePortを指定しています。
NodePortを指定すると、k8sクラスタを構成する全てのノードに、このサービスへ接続するためのエンドポイントが作成されます。.ports[*].nodePortで公開するポートを指定することもできますが、使用中のポートを指定するとエラーになります。無指定の場合は、30000-32767のレンジから自動的に割り当てられます。いずれの場合も、ポート番号は全てのノードで同じになります。
minikubeの場合、このサービスへ接続するためのURLはminikube service listで確認することができます。
% minikube service list|-------------|----------------------|----------------------------|| NAMESPACE | NAME | URL ||-------------|----------------------|----------------------------|| default | demoapp-mysql | No node port || default | demoapp-puma | http://192.168.64.25:32320 || default | demoapp-redis | No node port || default | kubernetes | No node port || kube-system | default-http-backend | http://192.168.64.25:30001 || kube-system | kube-dns | No node port || kube-system | kubernetes-dashboard | http://192.168.64.25:30000 ||-------------|----------------------|----------------------------|また、minikube service demoapp-pumaのようにServiceの名前をパラメータとして渡せば、そのURLをブラウザでオープンすることができます。典型的には、http://$(minikube ip):32320のようにminikube ipにランダムなポート番号を与えた形式のURLでアクセスできるようになります。
さて、前述のようにNodePortを指定するとk8sクラスタを構成する全てのノードにエンドポイントが用意されます。minikubeのようにシングルノード構成の検証用クラスタではこれで十分ですが、マルチノード構成の本番環境では不十分です。少なくとも負荷分散や可用性担保のためには前段にロードバランサが必要になるし、k8sの外側でロードバランサの管理をするのは面倒です。
外向けのエンドポイントにロードバランサを組み合わせる場合、通常はLoadBalancerタイプのServiceかIngressというオブジェクトを使います。次回Kubernetes応用編のStep4ではIngressを使ってこの問題に対処する方法を示します。
rails-env-cm.yaml: pumaとsidekiqに共通の環境変数用ConfigMap
下記のような内容です。MySQLやRedisのホスト名として、それぞれmysql-svc.yamlとredis-svc.yamlで定義したServiceオブジェクトの名前を指定しています。
# k8s/manifests-step1/rails-env-cm.yaml---apiVersion: v1kind: ConfigMapmetadata: name: demoapp-rails-envdata: RAILS_SERVE_STATIC_FILES: "true" RAILS_LOG_TO_STDOUT: "true" SIDEKIQ_TIMEOUT: "60" MYSQL_HOST: demoapp-mysql MYSQL_USER: demoapp MYSQL_DATABASE: demoapp_production REDIS_HOST: demoapp-redis REDIS_URL: redis://demoapp-redis:6379/1rails-env-secret.yaml: pumaとsidekiqに共通の環境変数用Secret
特筆すべき点は特にありません。
mysql-env-secret.yamlの説明の際にも述べたとおり、環境変数の値はこの時点では暗号化されていないため、実際の運用においては sopsやyaml_vault で暗号化するなどしてからgitリポジトリに含める必要があります。
# k8s/manifests-step1/rails-env-secret.yaml---apiVersion: v1kind: Secretmetadata: name: demoapp-rails-envdata: SECRET_KEY_BASE: MTIz # echo -n "123" | base64 MYSQL_PASSWORD: c2VjcmV0 # echo -n "secret" | base64sidekiq-deploy.yaml: sidekiq の Deployment
最後にsidekiq用のDeploymentの定義を見ます。
# k8s/manifests-step1/sidekiq-deploy.yaml---apiVersion: apps/v1kind: Deploymentmetadata: name: demoapp-sidekiq labels: app: demoapp component: sidekiqspec: replicas: 1 selector: matchLabels: app: demoapp component: sidekiq template: metadata: labels: app: demoapp component: sidekiq spec: restartPolicy: Always terminationGracePeriodSeconds: 65 containers: - name: sidekiq image: demoapp:0.0.1 imagePullPolicy: IfNotPresent command: - ./bin/start-sidekiq livenessProbe: exec: command: - ./bin/health-check-sidekiq initialDelaySeconds: 30 envFrom: - configMapRef: name: demoapp-rails-env - secretRef: name: demoapp-rails-env内容としてはほぼpuma-deploy.yamlと同じですが、下記の点に注目してください。
terminationGracePeriodSecondsはPodにTERMシグナルを送ってからプロセスの終了を待つ時間です。この時間を超えるとプロセスはKILLシグナルで強制的に停止されます。デフォルト値は30秒です(参考)。./bin/start-sidekiqでは-t $SIDEKIQ_TIMEOUTオプションをつけてsidekiqを起動しており、$SIDEKIQ_TIMEOUTにはrails-env-cm.yamlで60秒を指定しているので、terminationGracePeriodSecondsには65秒を設定しています。ローリングアップデートやコンテナ終了時の動作の詳細についてはStep2で説明します。livenessProbeはpumaと異なりexecタイプで独自実装のコマンドを呼び出します。内容については後述します。Serviceと接続しないためreadinessProbeは定義しません。envFromは完全にpumaと同じです。厳密にいうと環境変数SECRET_KEY_BASEは無くても動作するのですが、設定を簡素化するためにpumaと共通化しています。
sidekiqワーカープロセスの死活監視
sidekiqのワーカープロセスには、pumaのようなヘルスチェックのためのインタフェースがありません。sidekiqのオプションでPIDをファイルに書き出すようにすればプロセスの存在確認くらいはできるのですが、そもそもプロセスが停止しているようなケースではコンテナ自体が終了してしまうためk8s側で死亡判定できます。問題は何らかの原因でsidekiqプロセスが生きたまま応答しなくなっているようなケースをいかに検出するかです。
sidekiqのワーカープロセスは定期的に自身のホスト名やプロセスIDなどの情報をRedisに書き込んでいます。この処理はheartbeatと呼ばれています。(詳細はこの素敵な絵文字メソッドを参照)
heartbeatは5秒間隔で実行されますが、60秒間更新が無いと自動的にRedisから削除されるようになっています。heartbeatによってRedisに書き込まれたワーカーのリストはsidekiqのWeb UI上でも確認することができます。
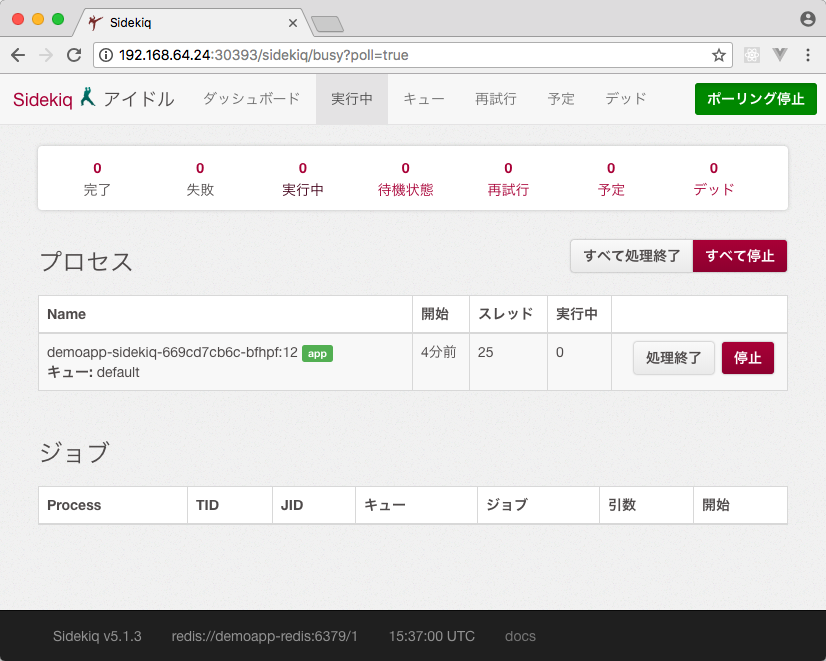
そしてこのワーカーのリストは、SidekiqのAPIでも取得することができます。
https://github.com/mperham/sidekiq/wiki/API#processes
k8sではPodのホスト名はPodの名前と同じになるのでユニークであることが保証されています。livenessProbeで実行しているスクリプト./bin/health-check-sidekiqでは、このAPIを利用してワーカーのリストに自身のホスト名が含まれているかどうかを確認しています。
#!/bin/bash -ecd $(dirname $0)/.../bin/rake sidekiq:status# lib/tasks/sidekiq.rakenamespace :sidekiq do desc "Health check for sidekiq worker process." task status: [:environment] do require "socket" hostname = Socket.gethostname if Sidekiq::ProcessSet.new.any? { |ps| ps["hostname"] == hostname } exit 0 else exit 1 end endend死活監視が意図したように動作するかどうかは、sidekiqプロセスにSIGSTOPシグナルを送ってサスペンドすれば確認できます。SIGKILLやSIGTERMなどでは即座にコンテナが終了するため、livenessProbeを待たずPodが再起動される点に注意してください。
$ kubectl get podsNAME READY STATUS RESTARTS AGEdemoapp-mysql-57d56b47cd-ztc5k 1/1 Running 0 2mdemoapp-puma-749c456c87-6vhrl 1/1 Running 0 2mdemoapp-redis-58f795f487-v2x4j 1/1 Running 0 2mdemoapp-sidekiq-669cd7cb6c-bfhpf 1/1 Running 0 2m$ kubectl exec demoapp-sidekiq-669cd7cb6c-bfhpf -- pgrep -l sidekiq31 sidekiq 5.1.3 app [0 of 25 busy]$ kubectl exec demoapp-sidekiq-669cd7cb6c-bfhpf -- pkill -STOP sidekiqこの後、60秒ほど待つとSidekiqのWeb UI上でワーカープロセスが消えるのを確認できます。さらにその後、だいたい10秒に一度の頻度でヘルスチェックが失敗したというログがsidekiqのPodのイベントログに表示されます。3回失敗したところでコンテナがKillされて再起動し、再びSidekiqのWeb UI上に新しいワーカーが現れるのを確認できます。
$ kubectl get pods --watchNAME READY STATUS RESTARTS AGEdemoapp-mysql-57d56b47cd-ztc5k 1/1 Running 0 3mdemoapp-puma-749c456c87-6vhrl 1/1 Running 0 3mdemoapp-redis-58f795f487-v2x4j 1/1 Running 0 3mdemoapp-sidekiq-669cd7cb6c-bfhpf 1/1 Running 0 3mdemoapp-sidekiq-669cd7cb6c-bfhpf 1/1 Running 1 5m$ kubectl describe pod demoapp-sidekiq-669cd7cb6c-bfhpf(省略)Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Scheduled 5m default-scheduler Successfully assigned demoapp-sidekiq-669cd7cb6c-bfhpf to minikube Normal SuccessfulMountVolume 5m kubelet, minikube MountVolume.SetUp succeeded for volume "default-token-dzvgp" Warning Unhealthy 42s (x3 over 1m) kubelet, minikube Liveness probe failed: Normal Pulled 11s (x2 over 5m) kubelet, minikube Container image "demoapp:0.0.1" already present on machine Normal Created 11s (x2 over 5m) kubelet, minikube Created container Normal Started 11s (x2 over 5m) kubelet, minikube Started container Normal Killing 11s kubelet, minikube Killing container with id docker://sidekiq:Container failed liveness probe.. Container will be killed and recreated.まとめ
Step1では、第2回Docker Compose/Dockerfile編のdocker-compose-preview.ymlに相当する構成をDeployment, Service, ConfigMap, Secretの4種のAPIオブジェクトで記述しました。
この時点では下記に挙げる三つの制約があります。
- pumaコンテナを複数起動すると
rails db:setupが並列実行されてエラーになる。 - MySQLやRedisのデータが永続化されていないため、コンテナを停止するとデータも消える。
- pumaに外部からアクセスするためのエンドポイントを本番環境で運用するのが難しい。
これらの制約を解消する方法は次回Kubernetes応用編で取り上げたいと思います。